In November 2002, two papers were presented at SC2002 — the ACM/IEEE Supercomputing conference, held that year in Baltimore. Software engineers at Sun Microsystems authored both papers, and I supported their efforts by providing data.
- SMP System Interconnect Instrumentation for Performance Analysis (IEEE Xplore), by Lisa Noordergraaf and Robert Zak
- Ultra-High Performance Communication with MPI and the Sun Fire Link Interconnect (IEEE Xplore), by Steven J. Sistare and Christopher J. Jackson
I worked closely with the paper authors to dig deep into benchmarks and performance metrics, reconfiguring hardware between benchmark runs and isolating workloads with interesting results within the benchmarks themselves. That’s the job I want to write about in this post - what performance engineering at a hardware company actually looked like in 2002, and why it was unlike most software work I have done before or since.
Performance Engineering Is a Different Kind of Software Job
Most software development is about building features. You take a requirement, you turn it into code, you ship it, and the measure of success is whether it does the thing it was supposed to do.
Performance engineering barely resembles that. I spent comparatively little time writing application code. Instead, I spent my time:
- Studying hardware. Reading processor manuals, interconnect specifications, and cache-coherence protocols closely enough to reason about them.
- Gathering performance metrics by running demanding math and science simulations — the kind of workloads that actually stress a machine.
- Analyzing the resulting data and, just as importantly, explaining my conclusions to people who would act on them.
- Building proof-of-concept implementations — not products, but small, sharp demonstrations that a particular change would move the needle on particular hardware.
The deliverable was usually not software. It was understanding. A performance engineer’s product is a defensible claim: “On this processor, with this workload, the bottleneck is here, and here is the evidence.” The two SC2002 papers are, in a sense, the polished public form of exactly that kind of claim.
What the Papers Were Actually About
Both papers orbit the same hard problem: in a large symmetric multiprocessing (SMP) machine, the system interconnect — the fabric tying processors, memory, and I/O together — is very often the thing that limits performance. Not the processors. The wiring between them.
The first paper describes hardware instrumentation embedded in the Sun Fire Link interconnect: programmable filters, histogramming counters, and a small transaction-sequence buffer that let performance analysts see what kinds of transactions were crossing the Sun Fireplane interconnect, where they were going, and which caches were involved. One noteworthy result is a cache-conflict detection tool: by capturing write-back transactions and computing which cache block each evicted address mapped to, you could literally produce a scatter plot of cache pain and point at the hot spot.
The second paper is about turning a rack of big SMP servers into a single capability cluster using the Sun Fire Link interconnect and a custom MPI library built on remote shared memory. The headline numbers — MPI ping-pong latency as low as 3.7 microseconds and inter-node bandwidths near 3 gigabytes per second — were striking enough that off-node performance often matched on-node performance. A job sometimes ran faster spread across two machines than packed into one. That work was funded in part through the U.S. Department of Energy’s ASCI PathForward program via Lawrence Livermore National Laboratory — supercomputing money, chasing supercomputing problems.
The Hardware Landscape of 2002: NUMA, OpenMP, and MPI
To appreciate why this work mattered, you have to remember what parallel computing looked like at the time.
By 2002 the free lunch of ever-faster single processors was visibly ending, and the industry’s answer was more processors — which immediately raises the question of how they share memory. A small SMP machine can pretend all memory is equidistant. A large one cannot. Physics intervenes: memory attached to the board your thread is running on is closer, and faster to reach, than memory three boards away. That is NUMA — Non-Uniform Memory Access — and it was becoming unavoidable. The cache-conflict tool in the first paper even reports which physical bank and system board each address lived on; locality was not an abstraction, it was a wiring diagram.
Software had two main answers, and the SC2002 papers touch both:
- OpenMP — a shared-memory model where you annotate code with compiler directives and the runtime spreads loops across threads. The first paper profiles applications from the SPEC OMP (SPEComp) suite.
- MPI — a message-passing model where independent processes explicitly send data to one another, the standard approach for spanning many machines. The second paper is an MPI implementation end to end, benchmarked with the NAS Parallel Benchmarks.
The reason a performance engineer cared about the parallel software stack and the hardware interconnect in the same breath is that they are the same problem viewed from two ends. An OpenMP directive that looks innocent in source code becomes a storm of cache-coherence traffic on the Fireplane bus. An MPI send becomes a remote memory write across an optical link. You cannot tune one layer well without instrumenting the other — which is exactly what these papers were built to do.
Reconfiguring the L2 Cache
Here is a small project that captures the strange privilege of being a software engineer at a hardware company.
I once had a task that involved changing the associativity of the L2 cache through processor configuration options, and then measuring the performance impact. Cache associativity is the trade-off between how flexibly a memory address can be placed in the cache and how expensive it is to look up — a direct-mapped cache is cheap but conflict-prone, a fully-associative cache is flexible but costly, and real designs sit somewhere in between.
The point is this: a consumer cannot change the associativity of their cache. It is a fixed property of the silicon they bought. But inside Sun, working on the hardware, I had access to configuration options that simply did not exist for anyone outside the building. I could take a real, production-class machine and ask it a question no customer could ask: what if this cache were organized differently? Then I could run real workloads and watch the answer fall out of the numbers.
That is the part of the job I keep coming back to. Performance engineering at a hardware company is partly an experimental science, and the company hands you instruments nobody else gets to touch.
UltraSPARC: From the 6502 of My Childhood to the Chips of Today
The Sun Fire servers behind these papers ran UltraSPARC III processors — the configuration in the MPI paper is an eight-node cluster of 24-processor servers, 192 CPUs at 900 MHz. Its successor, the UltraSPARC IV, arrived in 2004 and was Sun’s first dual-core chip — its first step into what Sun called chip multithreading. The UltraSPARC IV ran at 1.0–1.35 GHz, packed roughly 66 million transistors onto a 130-nanometer process from Texas Instruments, and let two cores share a large L2 cache.
Just for fun, let’s put a chip like that between the two ends of my own life with computers.
The consumer machines of my youth were powered by the MOS Technology 6502 — the 8-bit processor inside the Apple II, the Commodore 64, the Atari home computers, and the Nintendo Entertainment System. Designed by a small team under Chuck Peddle and launched in 1975, the 6502 had roughly 3,500 transistors, ran at about 1 MHz (MHz!), and famously sold for around $25 at a time when competing chips cost closer to $200. That price is most of the reason I could afford to buy my own Atari 130XE as a teenager.
| MOS 6502 (1975) | UltraSPARC IV (2004) | Modern desktop CPU (2025) | |
|---|---|---|---|
| Word size | 8-bit | 64-bit | 64-bit |
| Clock speed | ~1 MHz | 1.0–1.35 GHz | ~5 GHz |
| Cores | 1 | 2 | 8 to 24+ |
| Transistors | ~3,500 | ~66 million | tens of billions |
| Process node | ~8 µm | 130 nm | 3–5 nm |
| On-chip cache | none | up to 16 MB L2 | 10-100 MB L2, L3 |
Three numbers, three eras. The 6502 had no cache at all — main memory ran at processor speed, so there was nothing to hide. The UltraSPARC IV is the middle act: caches measured in megabytes, two cores, the interconnect becoming the bottleneck. Today’s desktop chips push past 5 GHz with dozens of cores and transistor counts in the tens of billions. The thing that did not change is the lesson of these papers: as you add cores, the hard problem migrates from the processor to everything around the processor.
A note on benchmarks, because the user-facing way to ask “how fast is this chip” today is a site like PassMark. I went looking, and PassMark — sensibly — does not carry processors this old; its database is built around chips people still buy. In 2002 the lingua franca was SPEC CPU2000 from the Standard Performance Evaluation Corporation, normalized so that a 300 MHz Sun Ultra 5 scored exactly 100. UltraSPARC servers of the era posted SPECint2000 results in the several-hundreds. Comparing that to a five-figure PassMark score on a modern CPU is apples to oranges — different benchmarks, different normalization — but the order-of-magnitude story is real, and SPEC is where the era’s serious numbers actually live.
Computer Architecture and Four Copies of Patterson and Hennessy
Computer architecture is one of my favorite subjects, and it has produced a strange effect on my book inventory: I have owned four copies of Computer Architecture: A Quantitative Approach by Patterson and Hennessy. One in undergrad. A newer revision in grad school. Another while I worked at Sun. And a fourth as a course textbook when I taught as an adjunct at Christopher Newport University. Reusing an older edition would never do, because the technology changes so fast the old information becomes unreliable.
| Edition | Year |
|---|---|
| 1st | 1990 |
| 2nd | 1996 |
| 3rd | 2002 |
| 4th | 2006 |
| 5th | 2011 |
| 6th | 2017 |
| 7th | 2025 |
Editions of Computer Architecture: A Quantitative Approach.
David Patterson led the Berkeley RISC project, whose RISC-I prototype (1982) used 44,000 transistors yet outran conventional designs with more than twice that count — and whose RISC-II became the direct ancestor of SPARC, the architecture I spent my Sun years measuring. John Hennessy led the Stanford MIPS project — MIPS standing for Microprocessor without Interlocked Pipeline Stages — and went on to co-found MIPS Computer Systems. The people who wrote the book on computer architecture had, quite literally, designed the architectures the book was about. They shared the 2017 ACM A.M. Turing Award for that work. When I sat in a Sun cubicle profiling SPARC silicon, I was poking at Patterson’s RISC lineage.
Teaching It: A Verilog Pipeline at CNU
When I taught this material at Christopher Newport, in Spring 2014, the course was cross-listed as CPEN 414 / CPSC 521 / PHYS 521, and the catalog spelled the centerpiece out plainly: “Architectural simulation using VERILOG.” The semester project was a 5-stage pipelined MIPS CPU written in Verilog, built up from a skeleton and then extended with RAW data-hazard detection, forwarding from MEM and WB, pipeline stalls when forwarding could not save you, and branch handling with delay slots.
The tool stack was deliberately open-source so every student could install it on their own laptop:
- Icarus Verilog — the open-source Verilog compiler and simulator. CLI with commands like
iverilog -g2005 -o MIPS *.v; run the resulting simulation directly. - GTKWave — the waveform viewer for VCD (Value Change Dump) files. When a stall did not fire on the cycle it should have, this is where you went to look: stage by stage, signal by signal, clock by clock.
- Verilog testbenches driving
$displayoutput, captured to.outfiles and diffed against.checkfiles — a small but effective regression harness, so a student tweaking forwarding logic could verify they had not just quietly broken the branch tests. - QEMU — used to host a MIPS Linux environment so the standard GNU
asandobjdumpcould turn.asmprograms into the hex memory images the simulated CPU would actually execute. - Fun aside: You can always tell you are looking at a hardware site when it looks like it was made in the 1990s. Click some of the links above, and you’ll see that I am right.
Helping students navigate this complex stack and fix there issues was always the part of teaching I enjoyed the most.
A Pet Peeve: CISC vs. RISC Is an Outdated Mental Model
Now for something I will happily discuss in more detail in the comments below.
Many engineers carry a mental model that sorts CPUs into two bins: CISC and RISC. It is a tidy story, and it is stuck in the early 1980s.
When RISC was new, it bundled together a set of genuinely fresh ideas: a generous file of general-purpose registers, instruction pipelining to extract parallelism — which was novel at the time — and fixed-size instructions that made decoding cheap and predictable. CISC machines, the story went, were the opposite of all that.
But that contrast quietly stopped being true. Modern CISC processors adopted nearly every one of those RISC improvements — big register files, deep pipelines, the works — with one holdout: variable-length instructions. A modern x86 chip is, internally, a RISC-style engine. It decodes its instruction set into simple, RISC-like micro-operations and executes those. The handful of genuinely complex, baroque instructions that gave CISC its name are still in the Instruction Set Architecture for compatibility, but compilers rarely emit them anymore, so the chip dedicates a large decode engine to handling them gracefully while optimizing hard for the common, RISC-like case. (This is not a recent trick — AMD’s K5 and Intel’s P6 were doing it back in 1995. Intel’s 486 had a five-stage pipeline in 1989!)
The fix for the mental model is to stop conflating the instruction set architecture with the CPU. The ISA is a contract — a specification. The CPU is one hardware implementation of that contract. The cleanest proof is that both AMD and Intel build x86 processors: one ISA, many wildly different microarchitectures underneath. RISC and CISC describe a long-ago argument about ISA design philosophy; they tell you increasingly little about how the silicon in front of you actually works.
The Register-less Machine: Tanenbaum’s 1978 Paper
If you want evidence that “how should an instruction set be designed” is an old and unsettled question, look at Andrew Tanenbaum — the same Tanenbaum known for MINIX and a shelf of operating-systems textbooks — and his 1978 Communications of the ACM paper, Implications of Structured Programming for Machine Architecture.
Tanenbaum did something refreshingly empirical: he studied more than 10,000 lines of real, structured (GOTO-free) program text and asked what such programs actually do. The answer was lopsided — assignment, procedure call, return, and if statements accounted for around 93% of all executed statements, and the constants and variables involved were overwhelmingly small. From that data he proposed a machine designed for the code people really write.
The proposal was a stack-based machine with no general-purpose registers at all. Where a RISC design leans on a wide register file, Tanenbaum’s hypothetical CPU kept operands on a stack and used a tight, fixed-length encoding that he argued could shrink program size by a factor of three. To an engineer steeped in the register-file orthodoxy that RISC made gospel, “no registers” sounds almost heretical — and that is exactly why it is instructive. The ideas in that paper went on to influence stack-oriented intermediate forms; you can hear an echo of it decades later in the bytecode of the Java Virtual Machine. There has never been only one right way to build a CPU. There have been eras, each convinced of its own consensus.
What You Can Learn From a Single Graph
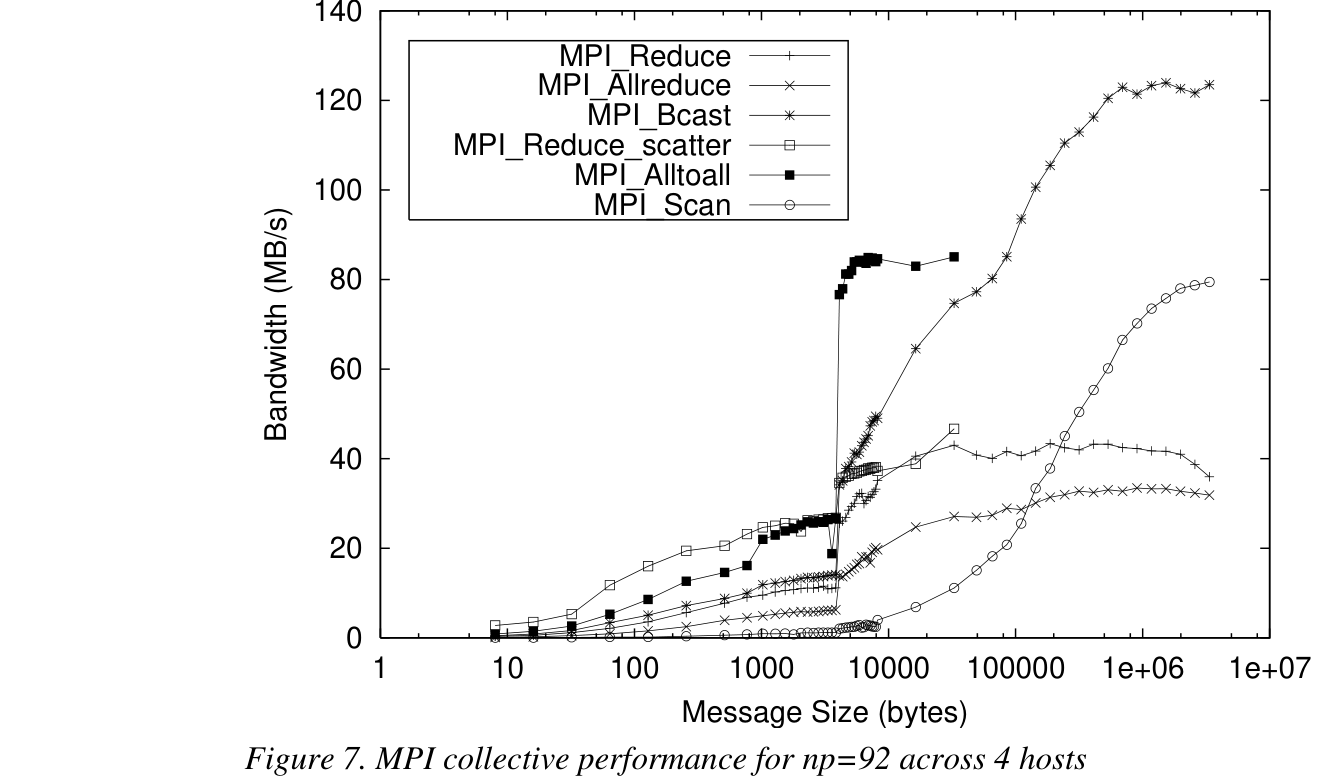
Figure 7 from Ultra-High Performance Communication with MPI and the Sun Fire Link Interconnect (Sistare & Jackson, SC2002): MPI collective bandwidth vs. message size, np=92 across 4 hosts. The near-vertical jump just past a few thousand bytes is the protocol transition described below.
Here is a concrete example of the kind of thing this research turns up — and a fitting lead-in to the last story. The graph above, Figure 7 from the second paper, plots the bandwidth of several MPI collective operations as the message size grows. Look at the near-vertical spike just past a few thousand bytes.
That spike is the MPI library changing gears. Below it, the short-message protocol is in effect: small messages are sent immediately, with no negotiation. Above it, the library switches to the long-message protocol, which coordinates sender and receiver with a handshake before the bulk of the data moves. The long protocol spends less time copying data into intermediate buffers and rides the natural efficiency of large transfers, so bandwidth climbs sharply once it takes over.
The deeper lesson is the shape of the solution: one cheap path tuned for small payloads, a different path tuned for large ones, with a threshold between them. That two-tier pattern recurs all over performance engineering — and, as it happens, it is exactly the shape of the last optimization I want to tell you about, one layer down, inside a single machine.
A Performance Win That Shipped: memcpy in the Solaris Kernel
As is frequently the case with fundamental research, most of our data, analysis, and results went on to be reviewed and debated among engineers and directors with no further deliverables. Let me close the loop on what this kind of research is for, by showing one improvement my team made that actually shipped.
Solaris was the Linux of the 2000s — the operating system quietly running an enormous share of the Internet’s backend servers — so a change deep in its kernel reached a lot of machines. The change in question was to memcpy, the humble routine that copies a block of bytes from one place to another.
It seems like there could not possibly be anything left to think about in copying bytes. There was.
One benchmarks used the compiler itself as the workload — specifically the SPEC CPU2000 integer test 176.gcc, which measures how fast a system can chew through a large batch of source code with GCC. It is a wonderfully realistic stress test: a compiler is a sprawling, pointer-heavy, memory-intensive program, and “how fast can this machine compile code” is a number developers genuinely care about.
What I found was that a CPU-driven copy outperformed a block copy on the GCC-driven benchmark — and the why is the interesting part. SPARC processors offered block load/store instructions that move large chunks of memory efficiently, but those operations tend to bypass the cache. My analysis showed that GCC has a very particular habit: it makes small copies of objects and then immediately mutates the copies. If a copy bypasses the cache, that immediate follow-up access pays for the miss. If instead you copy small objects with ordinary load/store instructions, both the original and the copy stay hot in cache, and the mutation that follows is nearly free.
So the conclusion was not “block copy is bad” — it was size-dependent: for certain processors, use load/store for small copies to keep the data cached, and keep the block copy for large copies where cache pollution does not matter. My capstone for that work was pushing for the improved library to ship in the next iteration of Solaris. It did. Somewhere out there, servers compiled code a little faster because of a few pages of cache analysis.
Looking Back
I want to end where I frequently start, by giving credit to the folks with PhDs. My role on these two papers was data gathering — running the workloads, capturing the counters, and working with the authors to chase down whatever a benchmark or a configuration turned up next. The ideas, the vision, the analysis and writing: that was a team of people far more senior than I was at the time, and it was an honor to contribute.
Gathering data is its own education. You learn to study hardware until you can argue with it. You learn that a performance claim is only as good as the measurement under it. And you learn that the most interesting bottleneck is almost never where you first looked — it is one layer down, in the interconnect, in the cache, in the gap between what the compiler emits and what the silicon prefers.
Twenty-some years later, with that 5th edition Patterson and Hennessy on the shelf behind my monitor, that is still a part of computing I find genuinely fun.
If this stirred up your own war stories — SPARC, Solaris, the cache-line trenches, or arguing about RISC at a whiteboard — let me know in the comments below.