Any sophomore computer science student knows that there are  permutations of any given array. But do you know how to produce those permutations? I didn’t , so I Googled it.
permutations of any given array. But do you know how to produce those permutations? I didn’t , so I Googled it.
One simple strategy is to pick an element, then pick from those remaining, and so on until a single permutation is achieved. Then just backtrack one step and change your selection, finish the permutation again, and so on. For example, if you want to permute ABCD :
- Select A
- Select B, yielding AB
- Select C, then D, yielding ABCD, your first permutation
- Back up two positions and select D, then C, yielding ABDC
- Back up three positions and select C, then B, then D, yeilding ACBD
- And so on…
This might be a pretty straightforward implementation using recursion and a running collection of element lists (several copies). This is memory and CPU intensive, so an in-place solution would be nice.
Heap’s algorithm provides an in-place swapping method to find each permutation in about one step each, so it is very efficient. It is named after B. R. Heap, not after your favorite semi-sorted tree.
The core idea is very intuitive: Hold the last element of your list while recursively permuting the other n-1 elements (one must understand recursion). Then swap that last element with one of the others, and permute n-1 elements again. This way you get every possible permutation of n-1 elements for every possible fixed element value at position n. This should get us all permutations.
The tricky part is swapping out the nth element for one of the others. You might be tempted to write a loop that picks a new element from the n-1 to swap with, but remember that we permute the n-1 elements at every step, effectively scrambling them. Take AB C as an example. The n-1 permute leaves us at BA C. Say we swap C with B, giving us CA B. The n-1 permute then takes us to AC B. We know that we should swap B with A, because that is the only choice left to sit at the fixed position. And it is at position 0, just like the previous swaps!
The six permutations produced look like this :
ABC -> BAC -> CAB -> ACB -> BCA -> CBA
Let’s apply the same swap-with-zero strategy to four elements, abbreviating the three-element permutations for clarity :
ABCD -..-> CBAD -> DBAC -..-> ABDC -> CBDA -..> DBCA -> ABCD --X..OOOPS
We started repeating permutations before finding all of them. It turns out that AB is a different kind of permutation than ABC because of the length.
To see why, start by assuming that our permutation method will, if run twice, return the same permutation it started with. (This can be proven through induction once we understand the whole algorithm, but I will leave out the proof.) When ABC is being permuted, the first two elements are permuted three times while the elements take turns at the right position. This odd number of permutations makes the first two elements unstable in the sense that, every time we swap in the nth element, they are in a different order.
But when ABCD is being permuted, the ABC scramble is being performed an even number of times (four times), so it is stable except for the swap of the nth element. It is easier to see if we look at the algorithm output right before it swaps the nth element:
BA -> AC -> CB
CBA -> CBD -> CAD -> BAD
BADC -> AECB -> EDBA -> DCAE -> CBED
CBEDA -> CBEDF -> CAEDF -> BAEDF -> BAECF -> BADCF
Notice that the odd-length scrambles are stable except for the one-character substitution, while the even-length ones are not. This is a hand-waving explanation at best, but it works to give us an intuitive understanding of the algorithm.
So, for even-length permutations, the n-1 swap is always done with the first element, while for odd-length permutations, the n-1 swap is done with the kth element, where k is a counter from position 0 to n-2 that increments every time we do this.
The recursion is still there, but with very little extra state, very few loops and conditionals. And it takes barely more than swaps, which is close to ideal. You can find the code in all its glory on Github, but here it is for your edification. Uncomment the console.log’s to see each operation in action.
var margin = ''
function permute(list, action) {
function swap(n,m) {
margin += ' '
//console.log(margin + 'swap ' + n + ' ' + m + (m==n ? ' (NOP)' : ''))
tmp = list[n]
list[n] = list[m]
list[m] = tmp
margin = margin.replace(/ $/,'')
}
function generate(n) {
margin += ' '
//console.log(margin + 'generate ' + n)
if (n==1) action(list)
else {
for (var i=0; i<n; i++) {
generate(n-1)
//console.log(margin + 'i = ' + i)
swap(n%2 ? 0 : i, n-1)
}
}
margin = margin.replace(/ $/,'')
}
generate(list.length)
}
permute(['A','B','C','D','E'], function(list){console.log(list)})
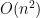 performance. If I manage to solve it using only sequential loops on the other hand, it would be
performance. If I manage to solve it using only sequential loops on the other hand, it would be  no matter how many loops I used. I think I scored somewhere in between, maybe
no matter how many loops I used. I think I scored somewhere in between, maybe 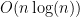 depending on what you believe about the inner loops in the following sections.
depending on what you believe about the inner loops in the following sections.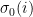 has
has  . I’m no number theorist, but I buy it. A factor of two is not even worth typing Math.floor() for, so I’ll leave the code alone as it now looks clean.
. I’m no number theorist, but I buy it. A factor of two is not even worth typing Math.floor() for, so I’ll leave the code alone as it now looks clean.