Solving coding puzzles can be fun and rewarding. Try HackerRank or CodeSignal. But solving them on a whiteboard during a job interview can be… more stressful than fun. The book Cracking the Coding Interview comes with high praise and recommendations from some of the industry’s top tech recruiters.
I’ve been on both sides of the tech interview process, and writing code without an IDE is something that every developer should at least try at some point in their career. I recently tackled a basic problem using Java that once stumped me.
A long time ago, a job interviewer asked me to create a string searching algorithm. Given strings A and B, simply find A if it occurs in B. It is always good to start by stating the basic facts and showing that the problem can be solved, even if the naive algorithm is algorithmically complex. I managed to implement a naive string search. Naive search is simple:
- Iterate over B using the index bindex
- Iterate over A using the index aindex
- Compare the character A[aindex] to the character B[aindex+bindex]
- If they are the same, proceed with the inner loop (over A)
- If they differ, break out of the inner loop (over A)
- If A’s loop completes, the string search has found a match
- Iterate over A using the index aindex
The big problem with this algorithm is that it works in 
I recently read about an optimized string search algorithm, and the old pain of defeat flared up again. I had to implement Rabin Karp.
Rabin Karp optimizes the inner loop in the following way:
- Create a hash-code for A. For example:
for (int index = 0; index < pattern.length(); index += 1) {
searchHashAccumulator = (searchHashAccumulator + search.charAt(index)) % hashIndex;
}
- Create a hash-code array of length B_length
- Iterate over B using the index bindex
- Compute a cumulative hash for each character in B by adding the character at bindex to the cumulative hash value.
- Store this hash in the array
for (int index = 1; index <= search.length() - pattern.length(); index += 1) {
// add new character
searchHashAccumulator += search.charAt(index + pattern.length() - 1);
// remove old character
searchHashAccumulator -= search.charAt(index - 1);
// add padding to protect against negative numbers
searchHashAccumulator += hashIndex;
// modulo
searchHashAccumulator %= hashIndex;
searchHashes[index] = searchHashAccumulator;
}
- Iterate over B as before, bindex blah blah blah
- This time, before executing the inner loop over A, check the hash code of A with the appropriate hash code for B at position bindex
- If they don’t match, short-circuit the inner loop. We never execute it.
- If they do match, go ahead and run through A as before to verify a match was found.
search: for (int searchIndex = 0; searchIndex < search.length() - pattern.length() + 1; searchIndex += 1) {
if (patternHash != searchHashes[searchIndex]) {
System.out.println("Optimize!");
continue;
}
for (int patternIndex = 0; patternIndex < pattern.length(); patternIndex += 1) {
if (pattern.charAt(patternIndex) != search.charAt(searchIndex + patternIndex))
continue search;
}
return searchIndex;
}
Our hash code will sometimes match even when the string is not found (false positive), but it usually won’t. If we assume this is the case, then the inner loop basically executes only a few times. This makes our new time complexity 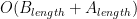
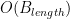
I implemented it with some JUnit test code on github. I plan to add code to this repo whenever I get the urge to try one of these coding puzzles to keep my coding tools sharp.